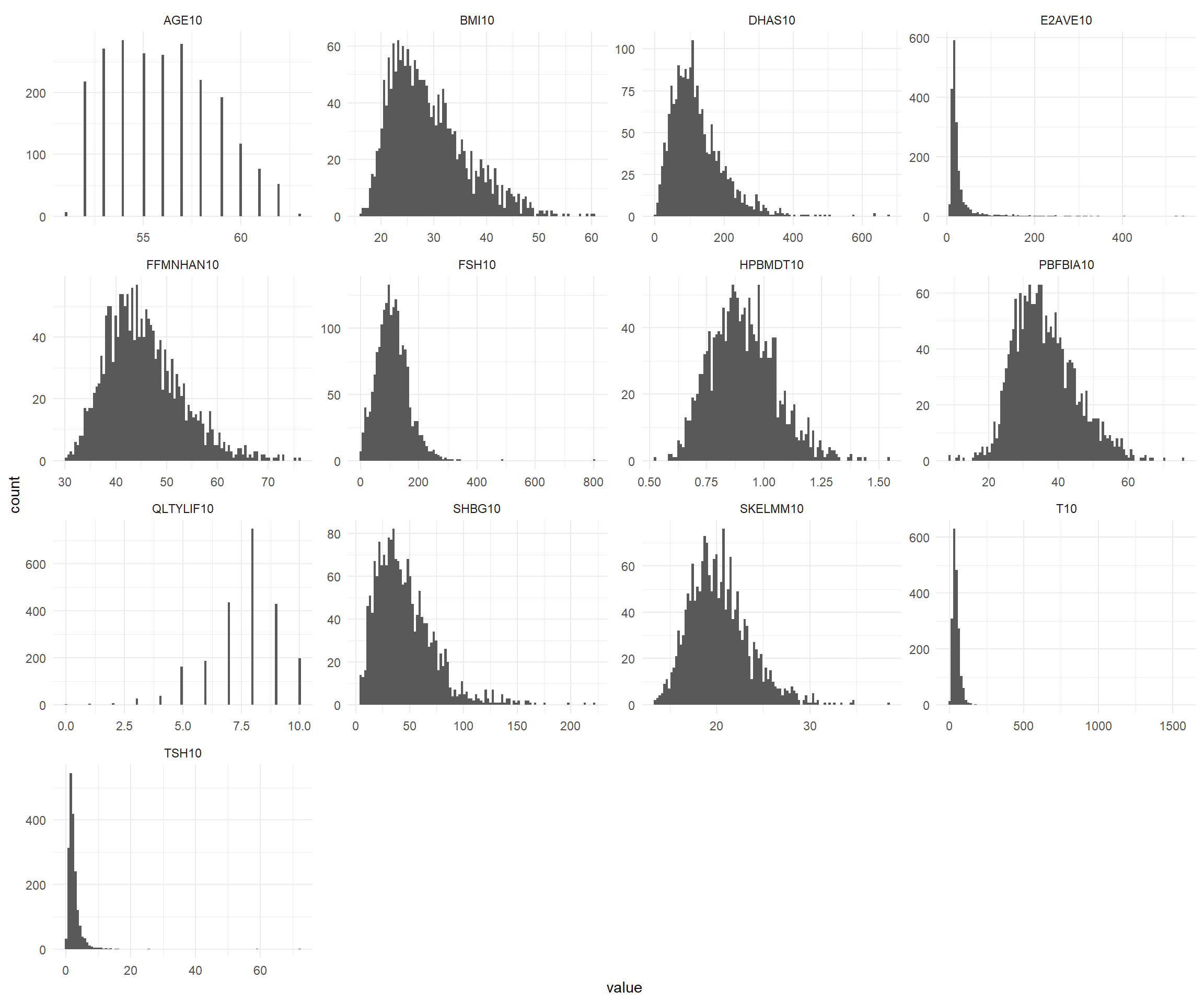
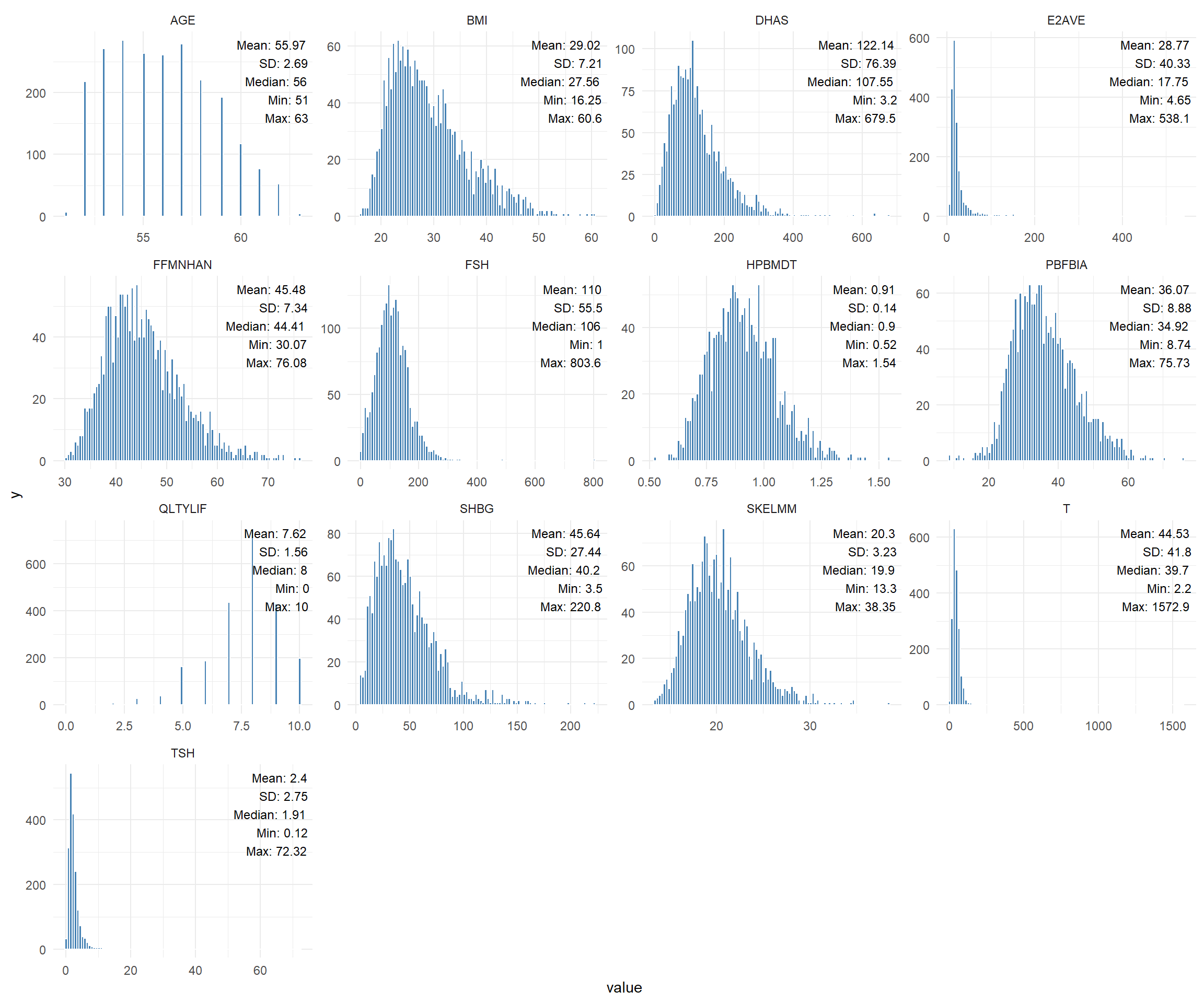
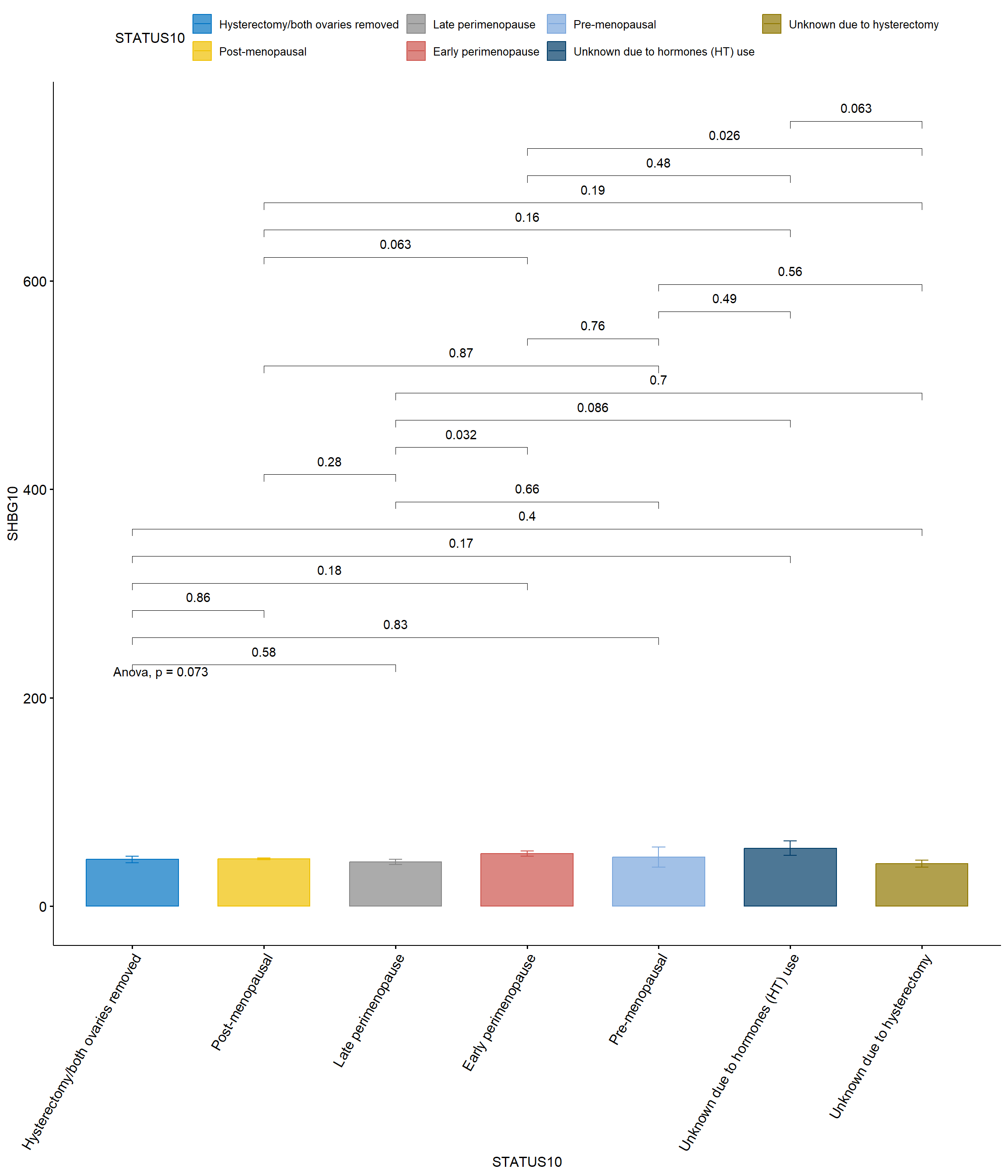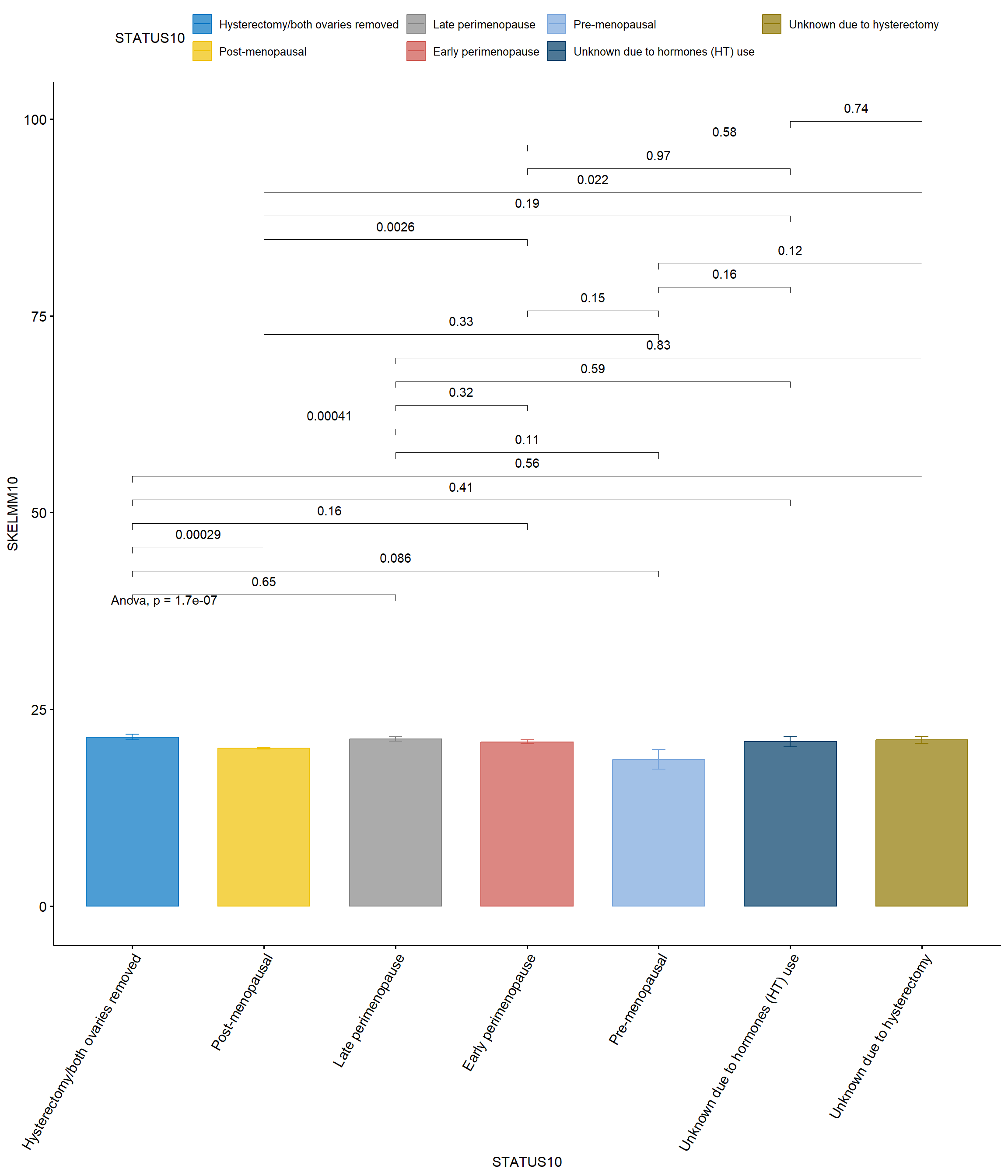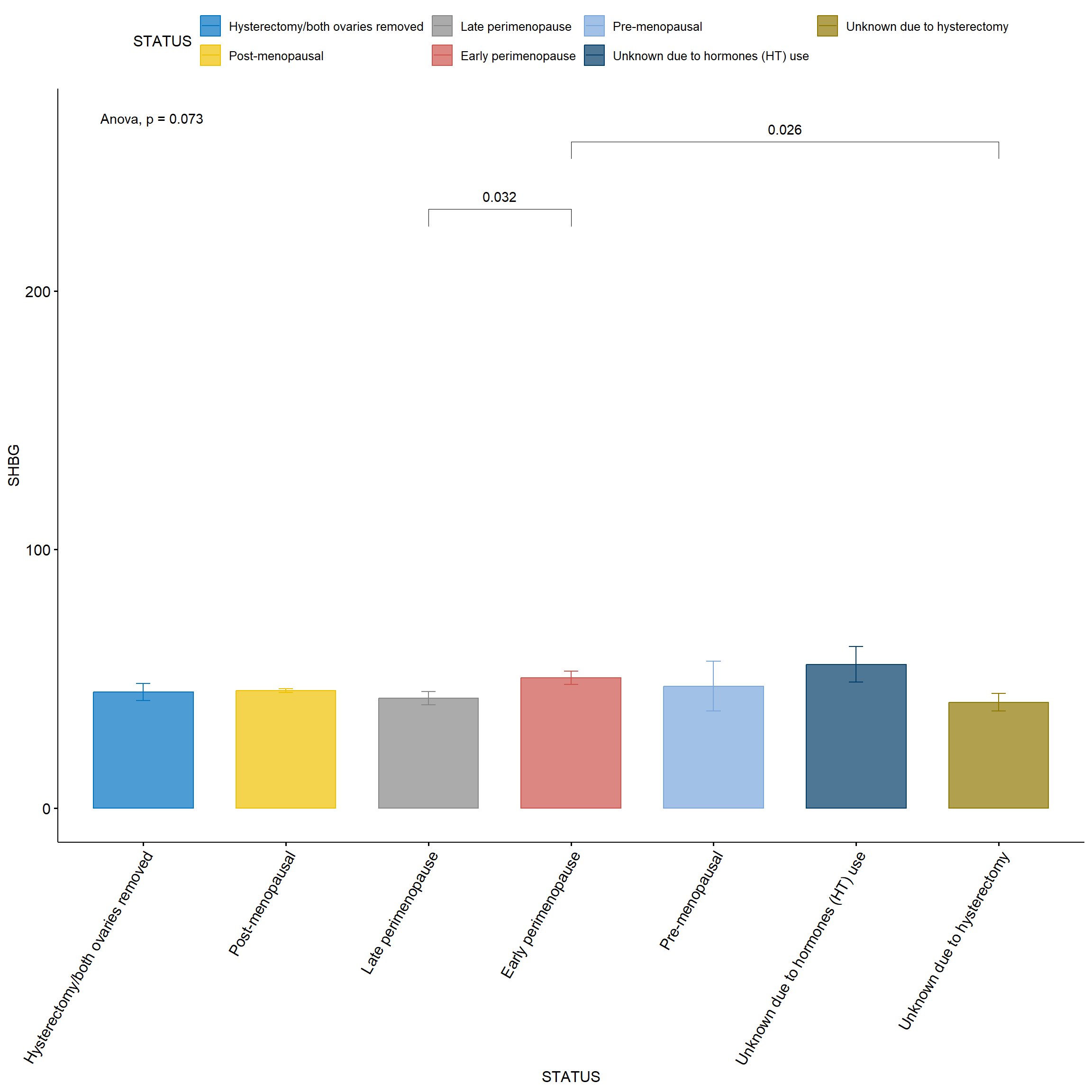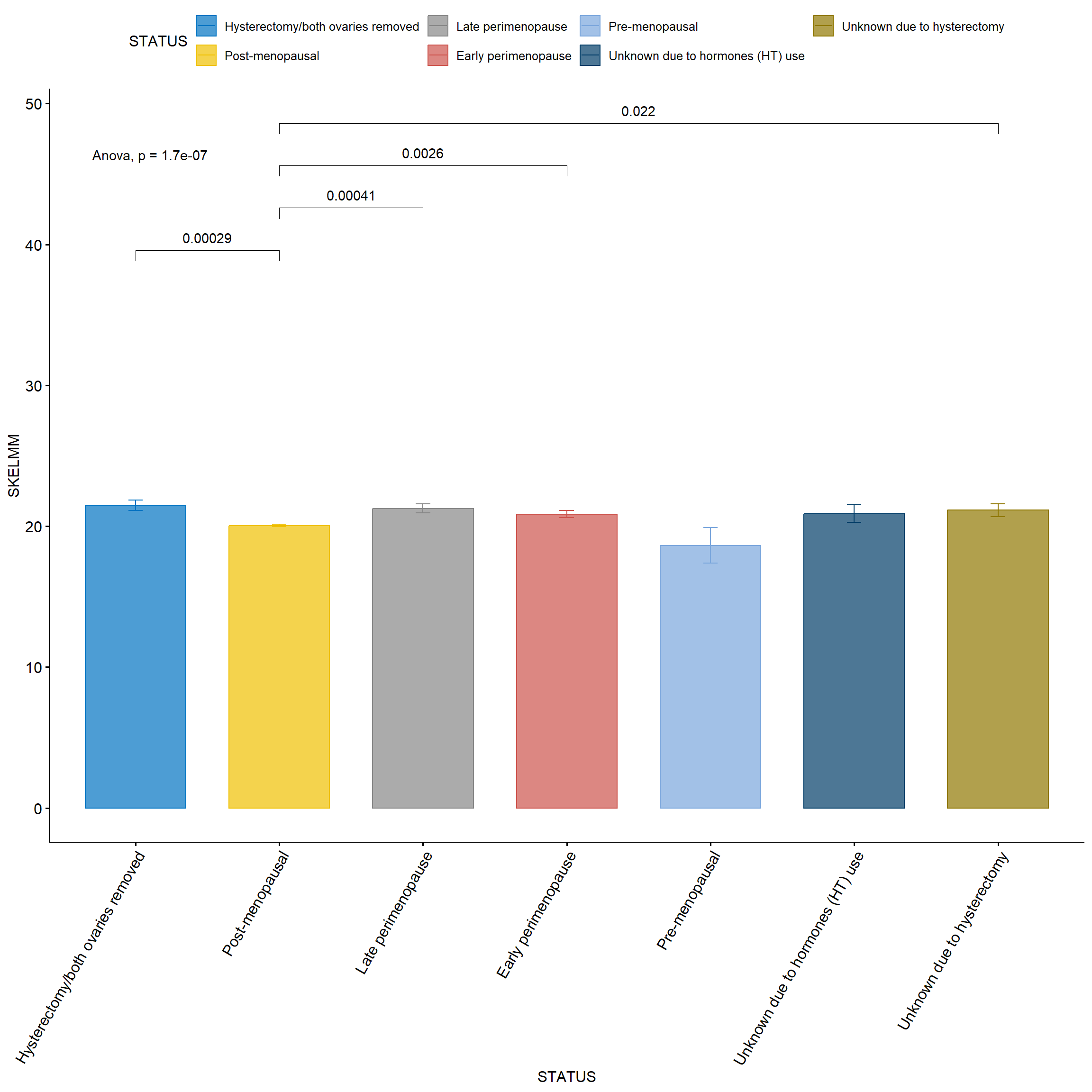SWANVISIT10_mod <- SWANVISIT10colnames(SWANVISIT10_mod) <-gsub("10$", "", colnames(SWANVISIT10_mod))# Primero transformamos los datos a formato largodatos_largos <-gather(SWANVISIT10_mod[,1:13], key ="key", value ="value")# Calculamos estadísticas por grupostats <- datos_largos %>%group_by(key) %>%summarise(mean =mean(value, na.rm =TRUE),sd =sd(value, na.rm =TRUE),median =median(value, na.rm =TRUE),min =min(value, na.rm =TRUE),max =max(value, na.rm =TRUE))# Ahora hacemos el gráficoggplot(datos_largos, aes(value)) +geom_histogram(bins =100, fill ="steelblue", color ="white") +facet_wrap(~key, scales ='free') +theme_minimal() +geom_text(data = stats, aes(x =Inf, y =Inf, label =paste0("Mean: ", round(mean,2), "\n","SD: ", round(sd,2), "\n","Median: ", round(median,2), "\n","Min: ", round(min,2), "\n","Max: ", round(max,2))),hjust =1.1, vjust =1.1, size =3.2, color ="black")
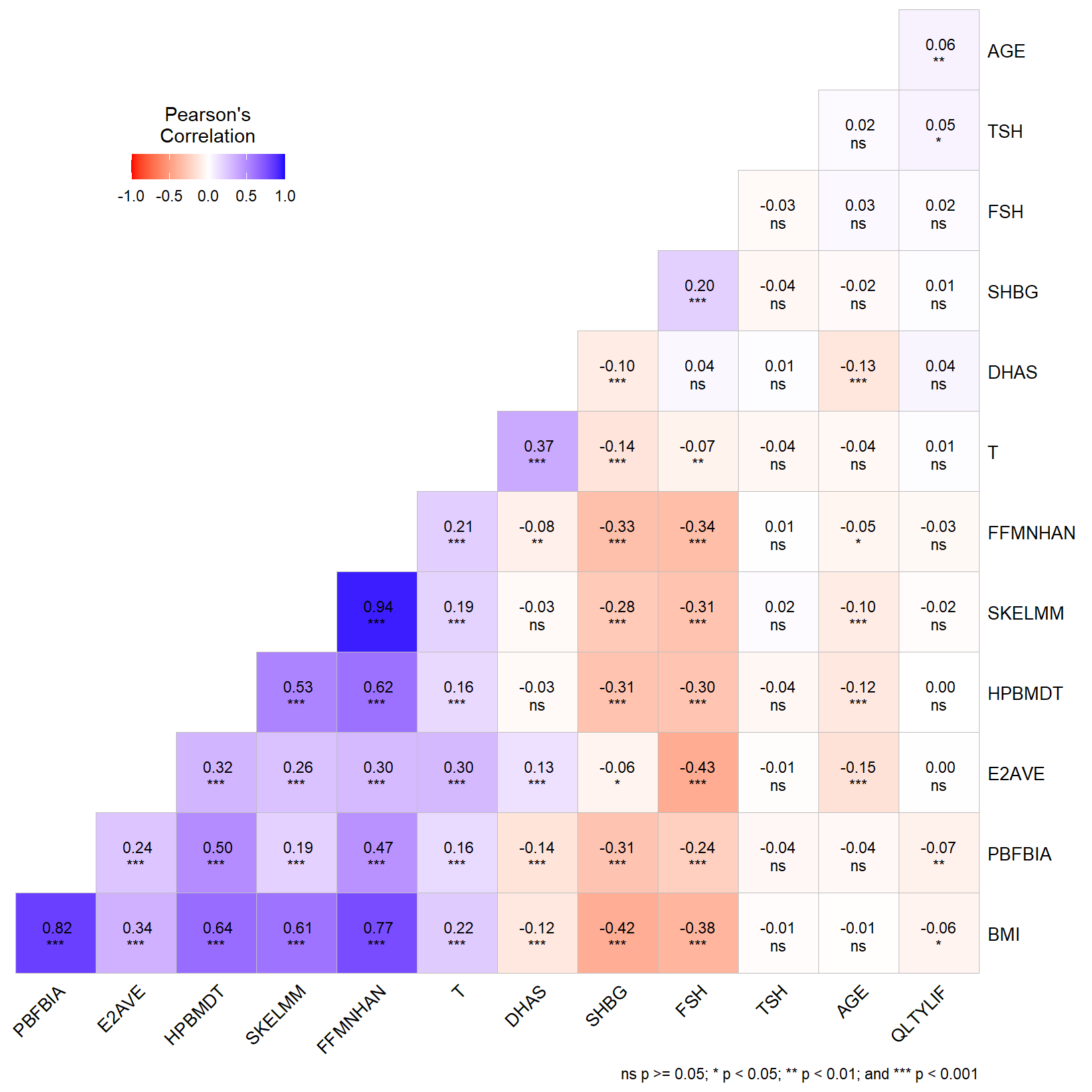
4 “r” Spearman correlation for continuous variables.
“r” > 0: direct relation. “r” < 0: inverse relation. “r” = 0: no relation.
-0.25<“r”<0.25: bad predictor
-0.5<“r”<-0.25 or 0.25<“r”<0.5: poor predictor
-0.5<“r”<-0.75 or 0.5<“r”<0.75: good predictor
“r”<-0.75 or “r”>0.75: excellent predictor.
Code
pairs.panels(SWANVISIT10[,1:13],smooth =TRUE, # If TRUE, draws loess smoothsscale =FALSE, # If TRUE, scales the correlation text fontdensity =TRUE, # If TRUE, adds density plots and histogramsellipses =TRUE, # If TRUE, draws ellipsesmethod ="spearman", # Correlation method (also "spearman" or "kendall")pch =21, # pch symbollm =FALSE, # If TRUE, plots linear fit rather than the LOESS (smoothed) fitcor =TRUE, # If TRUE, reports correlationsjiggle =FALSE, # If TRUE, data points are jitteredfactor =2, # Jittering factorhist.col ="grey70", # Histograms colorstars =TRUE, # If TRUE, adds significance level with starsci =TRUE) # If TRUE, adds confidence intervals
Code
# Crear un nuevo dataframe con los nombres de columnas modificadosSWANVISIT10_mod <- SWANVISIT10colnames(SWANVISIT10_mod) <-gsub("10$", "", colnames(SWANVISIT10_mod))all <-corr_coef(SWANVISIT10_mod[,1:13], method ="spearman")plot(all)
Code
png("correlation_plot.png", width =4000, height =3000, res =600) plot(all)dev.off()
png
2
*: p value < 0.05
**: p value < 0.01
***: p value < 0.001
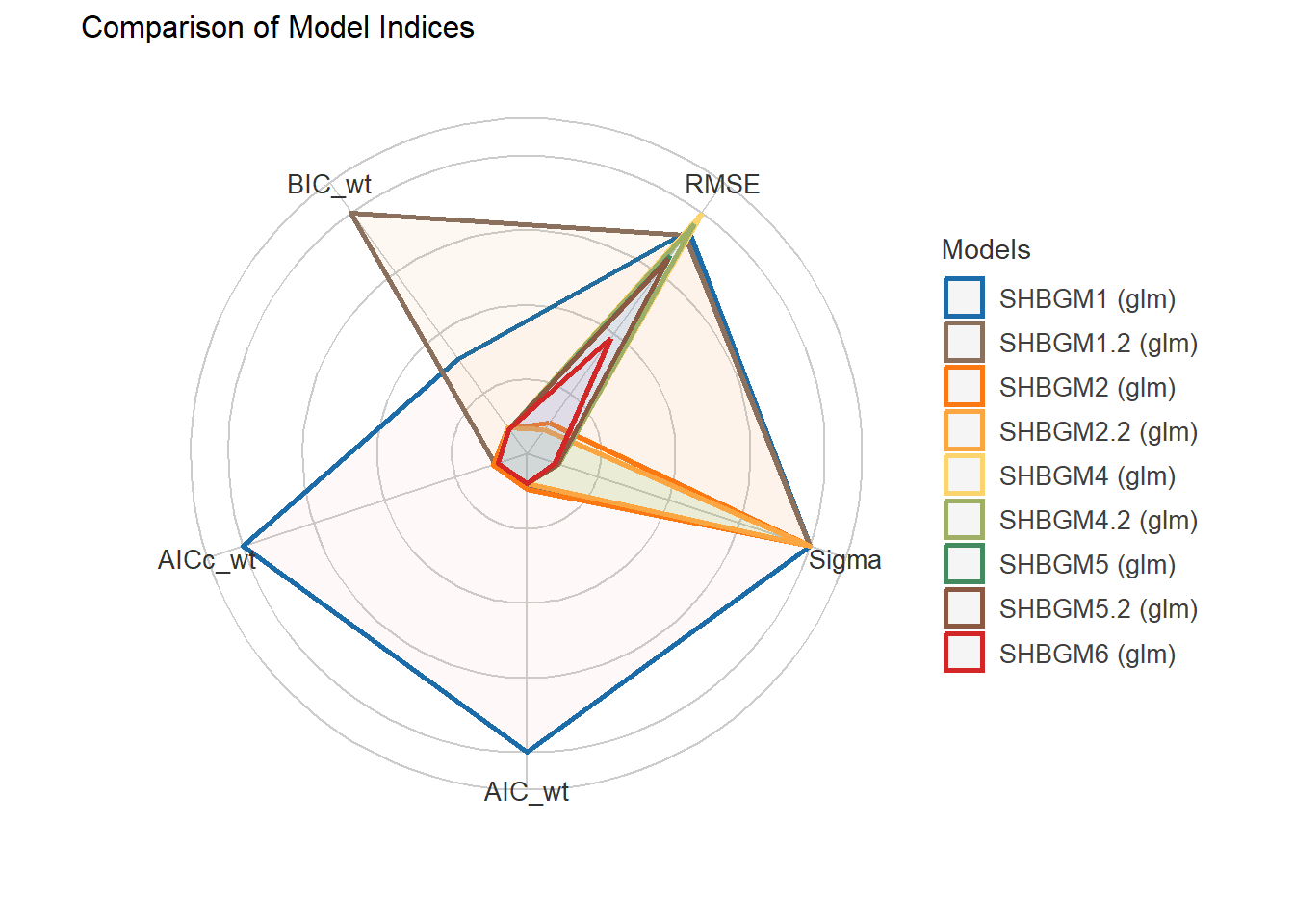
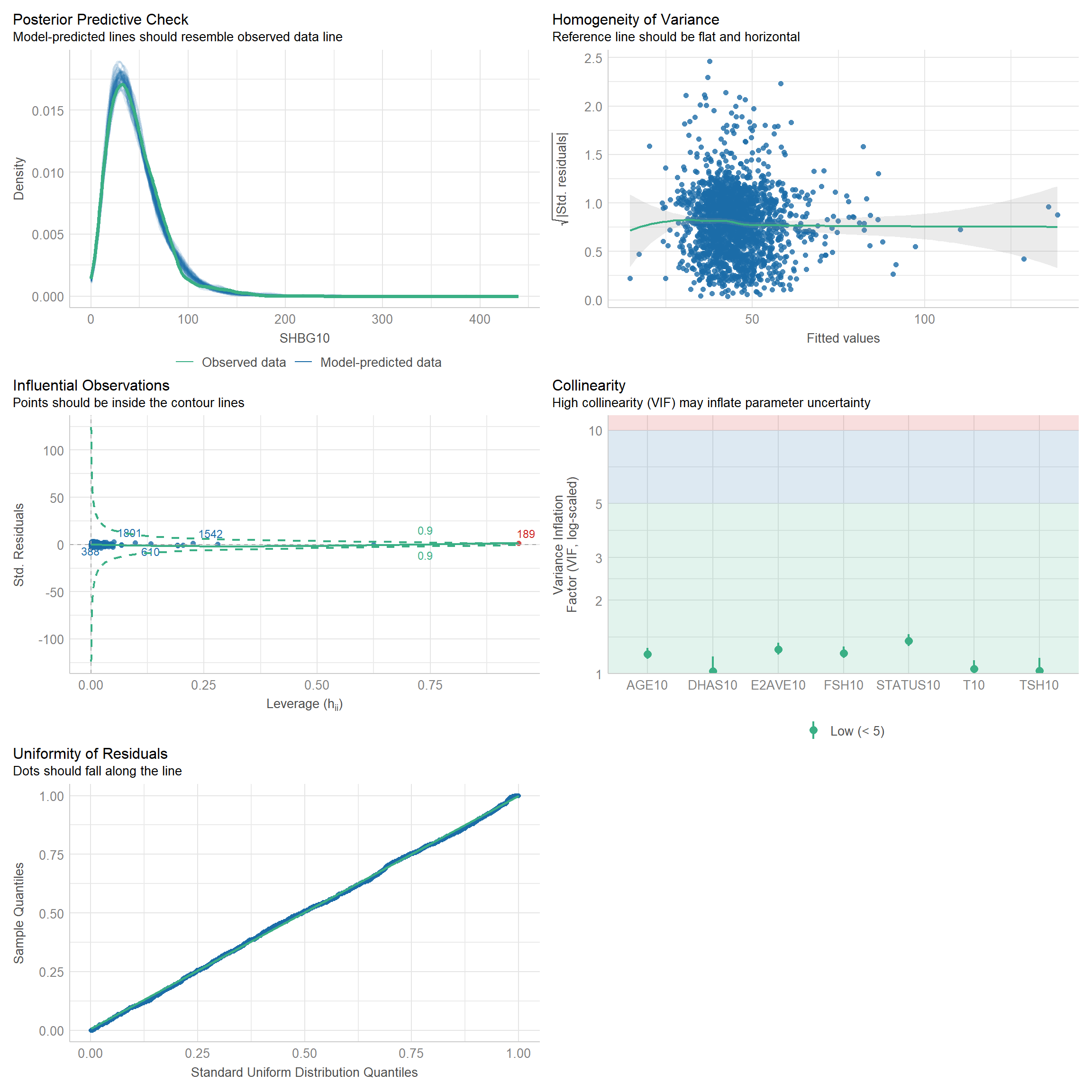
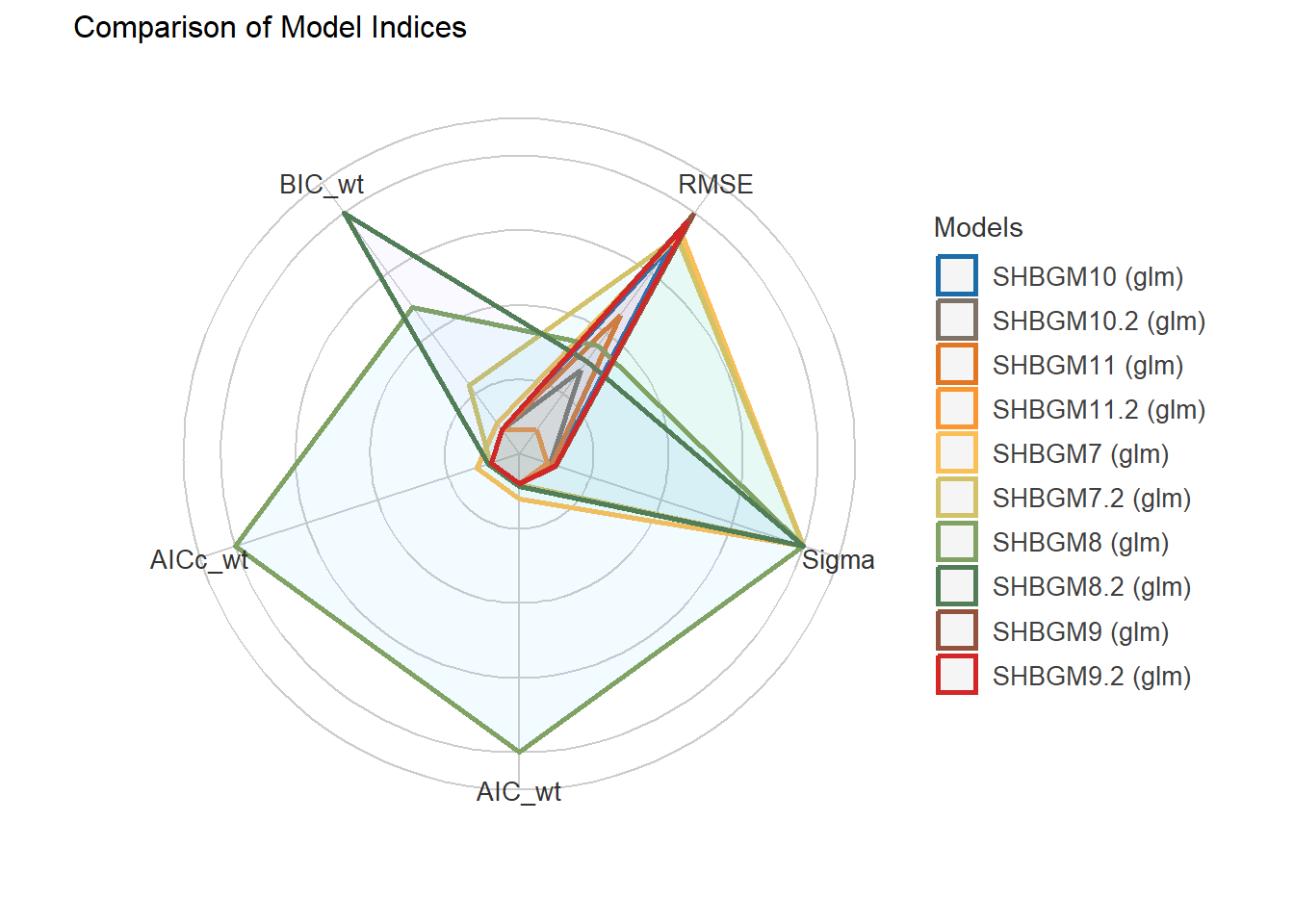
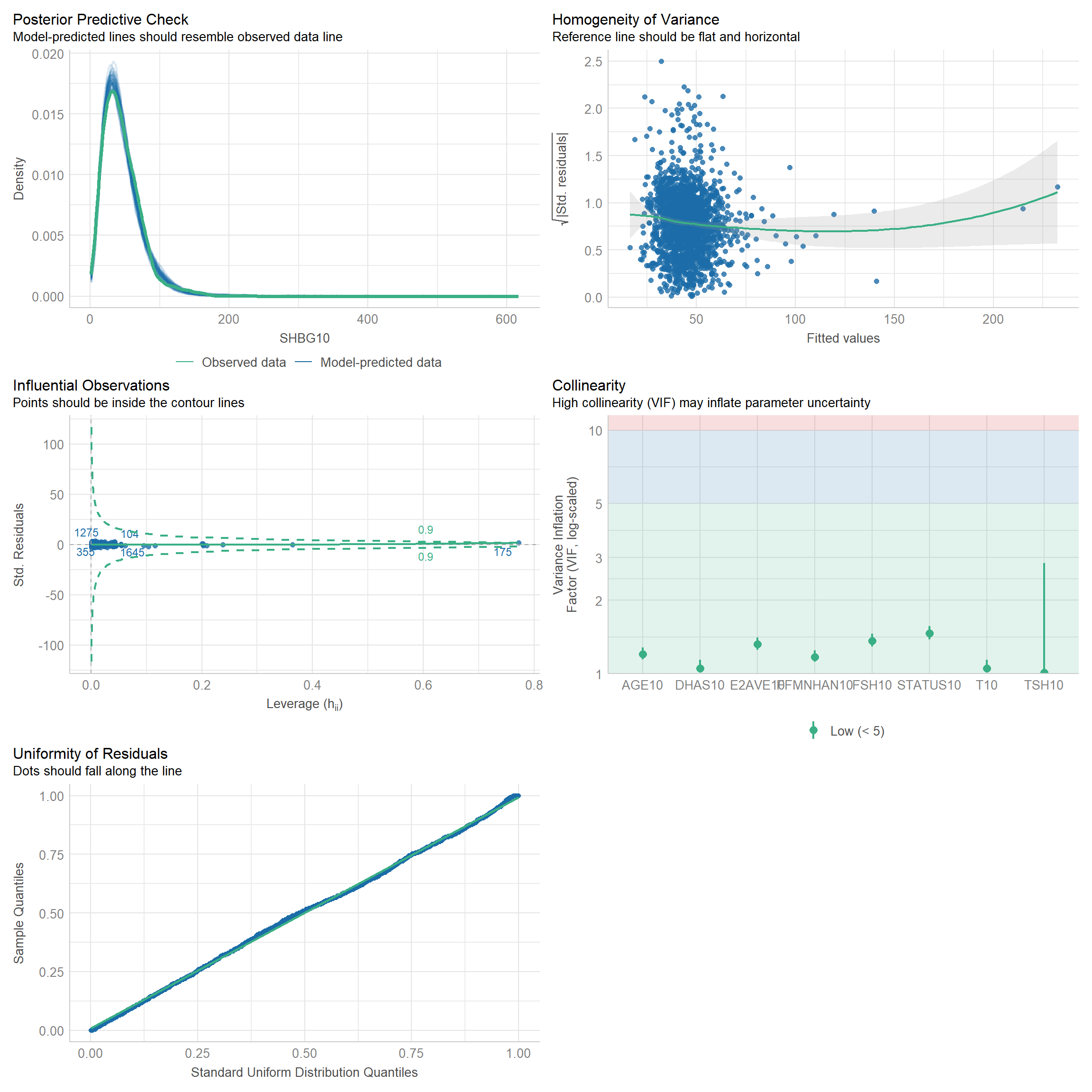
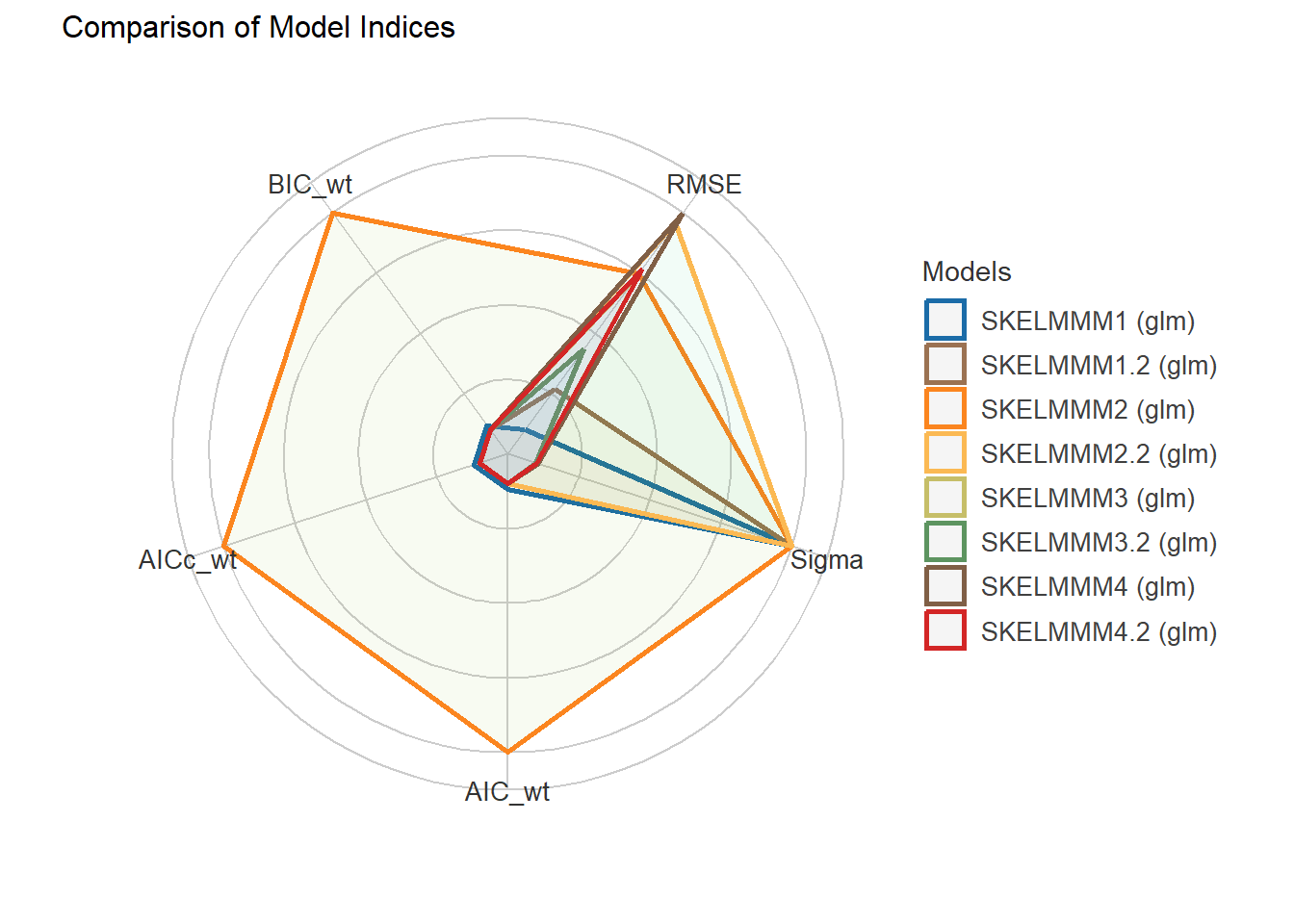
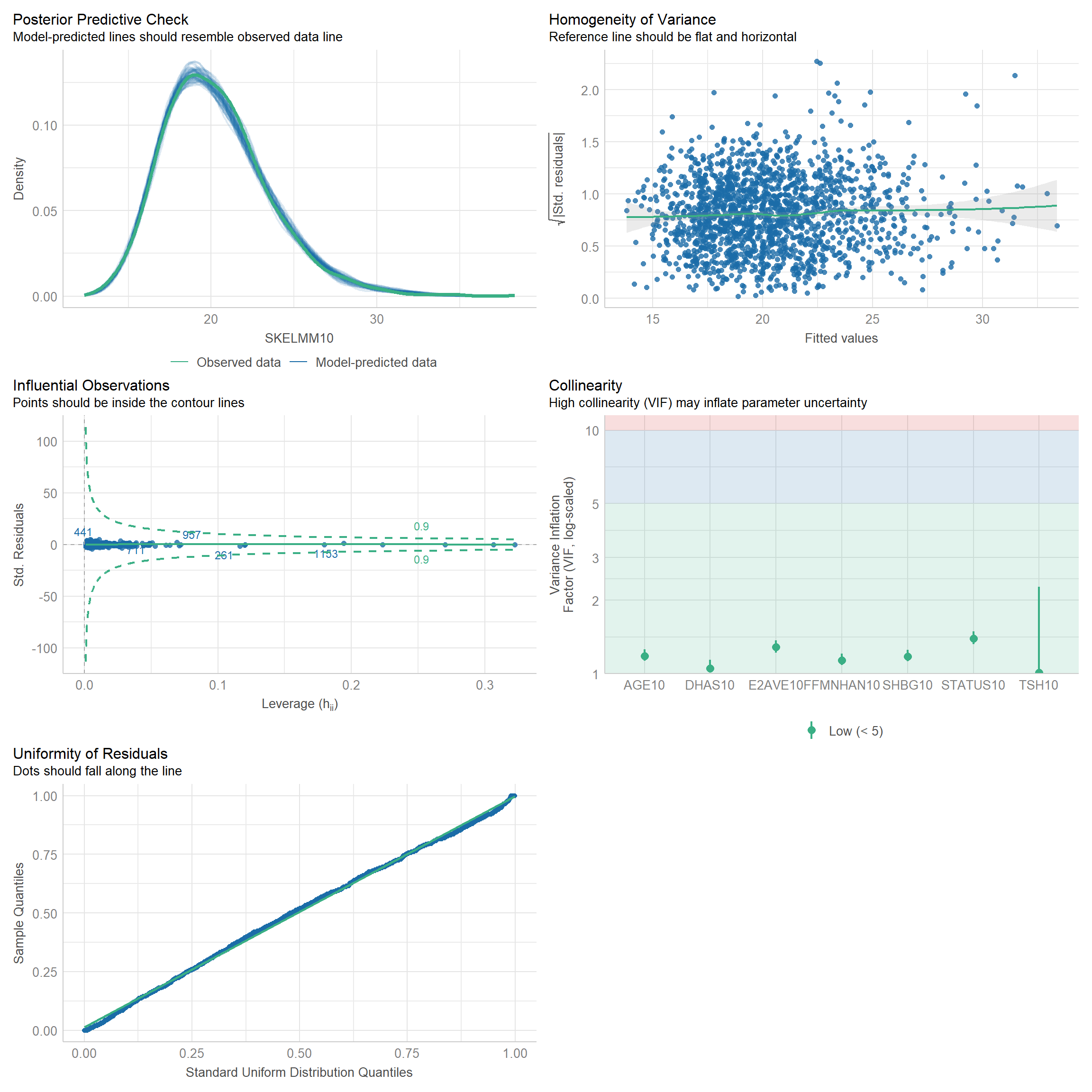
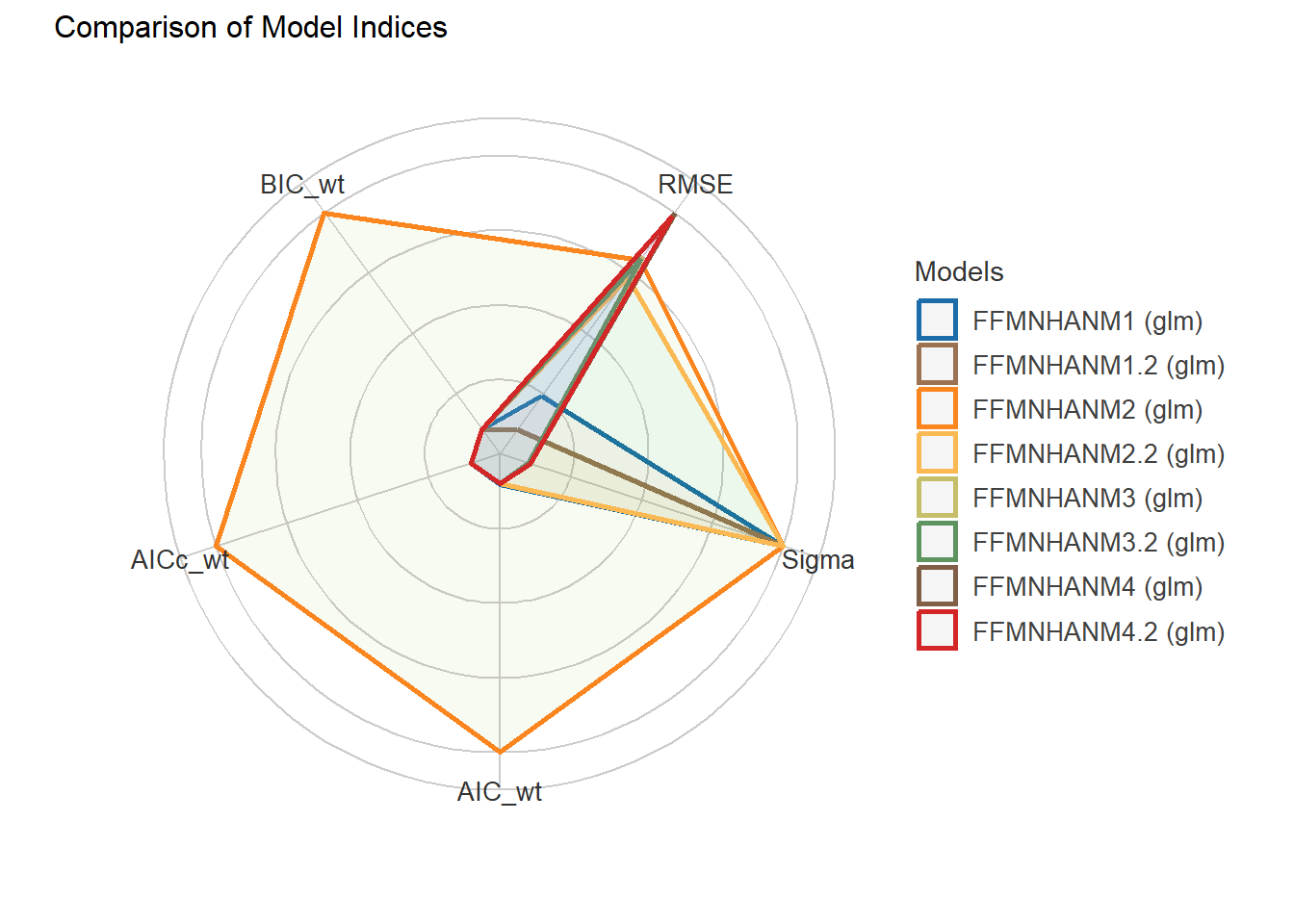
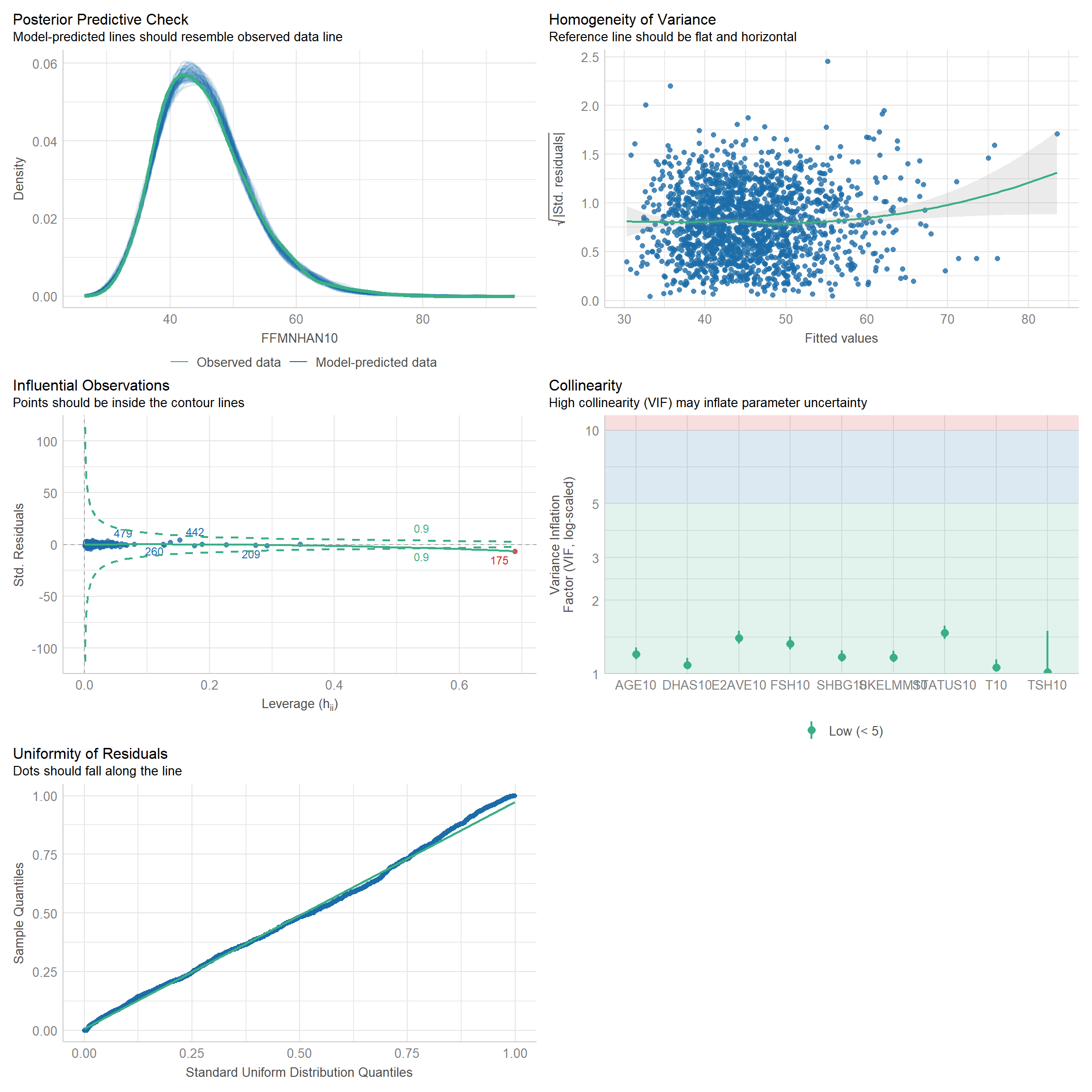
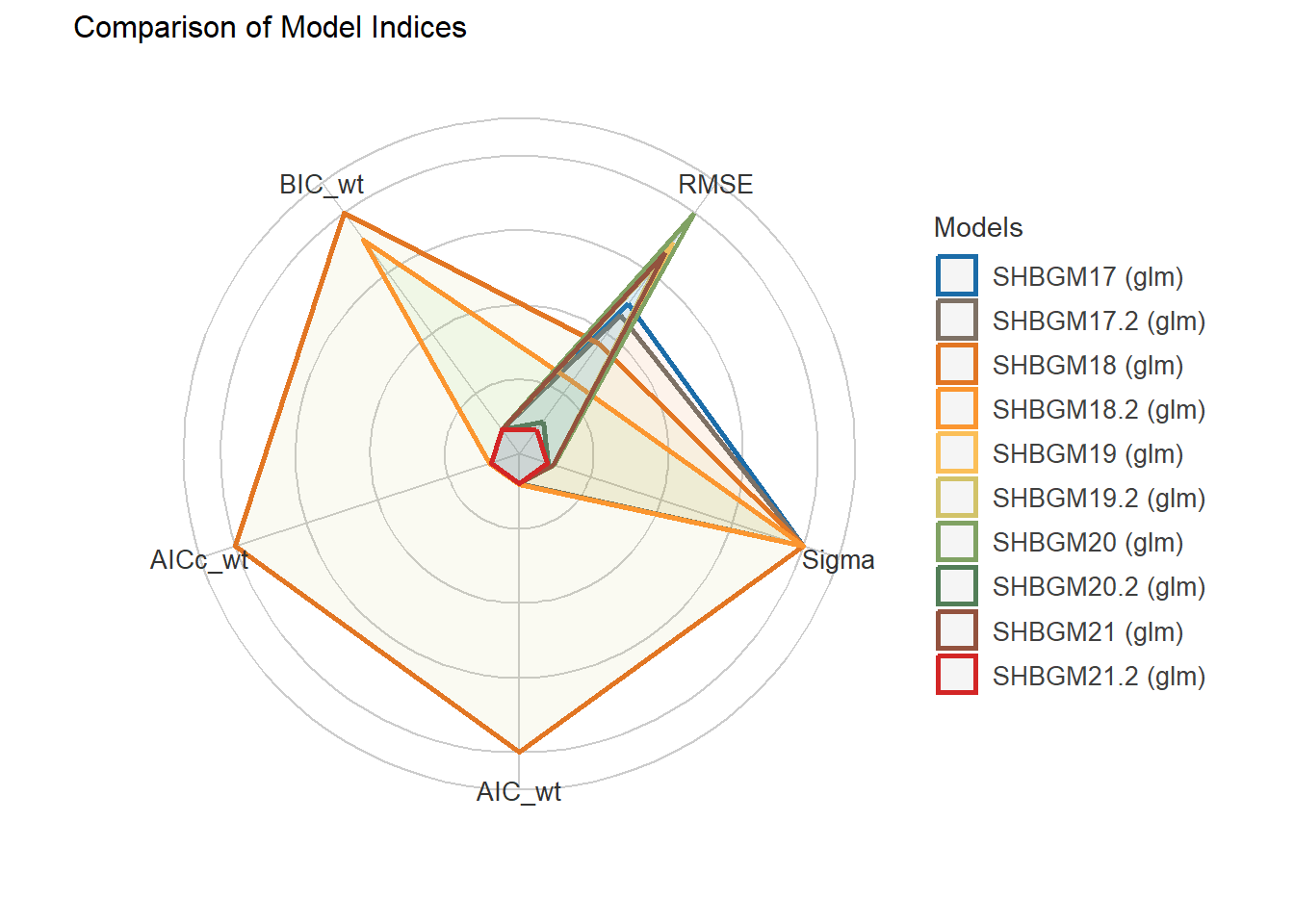
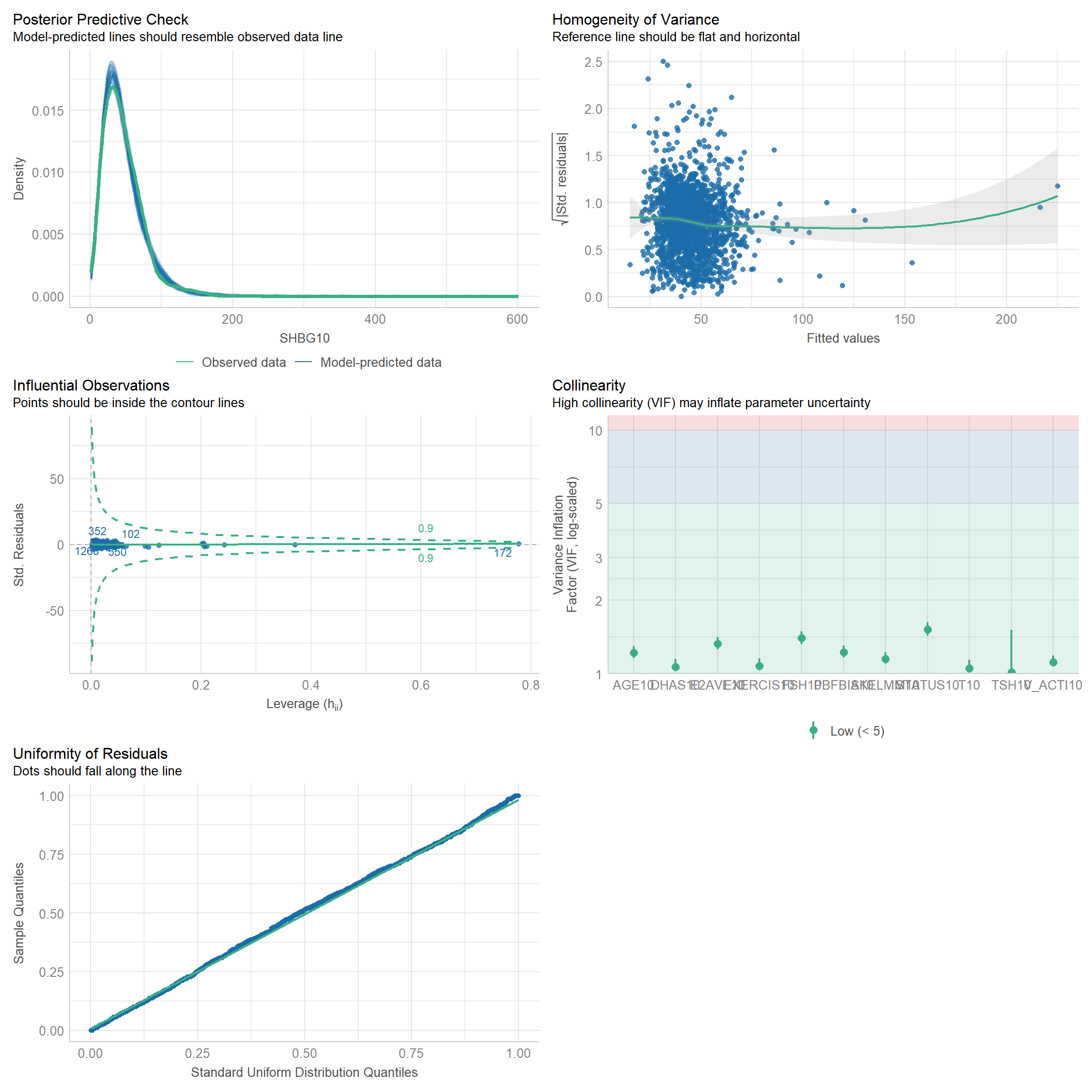
5 Generalized linear regression models (GLM) for dependent variable: SHBG.
5.1 Independent variable: Hormones + AGE + STATUS.
comparaciones <-list(c("Hysterectomy/both ovaries removed", "Late perimenopause"),c("Hysterectomy/both ovaries removed", "Pre-menopausal"),c("Hysterectomy/both ovaries removed", "Post-menopausal"),c("Hysterectomy/both ovaries removed", "Early perimenopause"),c("Hysterectomy/both ovaries removed", "Unknown due to hormones (HT) use"),c("Hysterectomy/both ovaries removed", "Unknown due to hysterectomy"),c("Late perimenopause", "Pre-menopausal"),c("Late perimenopause", "Post-menopausal"),c("Late perimenopause", "Early perimenopause"),c("Late perimenopause", "Unknown due to hormones (HT) use"),c("Late perimenopause", "Unknown due to hysterectomy"),c("Pre-menopausal", "Post-menopausal"),c("Pre-menopausal", "Early perimenopause"),c("Pre-menopausal", "Unknown due to hormones (HT) use"),c("Pre-menopausal", "Unknown due to hysterectomy"),c("Post-menopausal", "Early perimenopause"),c("Post-menopausal", "Unknown due to hormones (HT) use"),c("Post-menopausal", "Unknown due to hysterectomy"),c("Early perimenopause", "Unknown due to hormones (HT) use"),c("Early perimenopause", "Unknown due to hysterectomy"),c("Unknown due to hormones (HT) use", "Unknown due to hysterectomy"))ggbarplot(SWANVISIT10 %>%drop_na(STATUS10), x ="STATUS10", y ="SHBG10",add ="mean_se", # Agregar media y error estándarcolor ="STATUS10", fill ="STATUS10", # Colorear según STATUS10palette ="jco", alpha=0.7) +# Elegir una paleta de coloresstat_compare_means(method ="anova") +# Realizar ANOVAstat_compare_means(comparisons = comparaciones,method ="t.test", p.adjust.method ="bonferroni") +# Ajustar con Bonferronitheme(axis.text.x =element_text(angle =60, hjust =1))# Ajustar con Bonferroni
Code
ggbarplot(SWANVISIT10 %>%drop_na(STATUS10), x ="STATUS10", y ="SKELMM10",add ="mean_se", # Agregar media y error estándarcolor ="STATUS10", fill ="STATUS10", # Colorear según STATUS10palette ="jco", alpha=0.7) +# Elegir una paleta de coloresstat_compare_means(method ="anova") +# Realizar ANOVAstat_compare_means(comparisons = comparaciones,method ="t.test", p.adjust.method ="bonferroni") +# Ajustar con Bonferronitheme(axis.text.x =element_text(angle =60, hjust =1)) # Ajustar con Bonferroni
Code
# Primero, realiza las comparaciones y guarda los resultados# Realiza las comparaciones y guarda los resultadoscomparaciones_resultados <-compare_means( SHBG10 ~ STATUS10, data = SWANVISIT10 %>%drop_na(STATUS10),comparisons = comparaciones,method ="t.test",p.adjust.method ="bonferroni")# Filtra solo comparaciones significativas (p.adj < 0.05)comparaciones_significativas <- comparaciones_resultados %>%filter(p.format <0.05) %>%select(group1, group2) %>%pmap(c) # Esto genera una lista de vectores de caracteres# Ahora genera la gráfica solo con comparaciones significativasggbarplot(SWANVISIT10_mod %>%drop_na(STATUS), x ="STATUS", y ="SHBG",add ="mean_se",color ="STATUS", fill ="STATUS",palette ="jco", alpha =0.7) +stat_compare_means(comparisons = comparaciones_significativas,method ="t.test",p.adjust.method ="bonferroni") +stat_compare_means(method ="anova", label.y =max(SWANVISIT10_mod$SHBG, na.rm =TRUE) *1.2, # ligeramente arriba del valor máximolabel.x =0.7, # posición izquierdahjust =0) +# alineación izquierdatheme(axis.text.x =element_text(angle =60, hjust =1))
Code
# Primero, realiza las comparaciones y guarda los resultados# Realiza las comparaciones y guarda los resultadoscomparaciones_resultados <-compare_means( SKELMM10 ~ STATUS10, data = SWANVISIT10 %>%drop_na(STATUS10),comparisons = comparaciones,method ="t.test",p.adjust.method ="bonferroni")# Filtra solo comparaciones significativas (p.adj < 0.05)comparaciones_significativas <- comparaciones_resultados %>%filter(p.format <0.05) %>%select(group1, group2) %>%pmap(c) # Esto genera una lista de vectores de caracteres# Ahora genera la gráfica solo con comparaciones significativasggbarplot(SWANVISIT10_mod %>%drop_na(STATUS), x ="STATUS", y ="SKELMM",add ="mean_se",color ="STATUS", fill ="STATUS",palette ="jco", alpha =0.7) +stat_compare_means(comparisons = comparaciones_significativas,method ="t.test",p.adjust.method ="bonferroni") +stat_compare_means(method ="anova", label.y =max(SWANVISIT10_mod$SKELMM, na.rm =TRUE) *1.2, # ligeramente arriba del valor máximolabel.x =0.7, # posición izquierdahjust =0) +# alineación izquierdatheme(axis.text.x =element_text(angle =60, hjust =1))
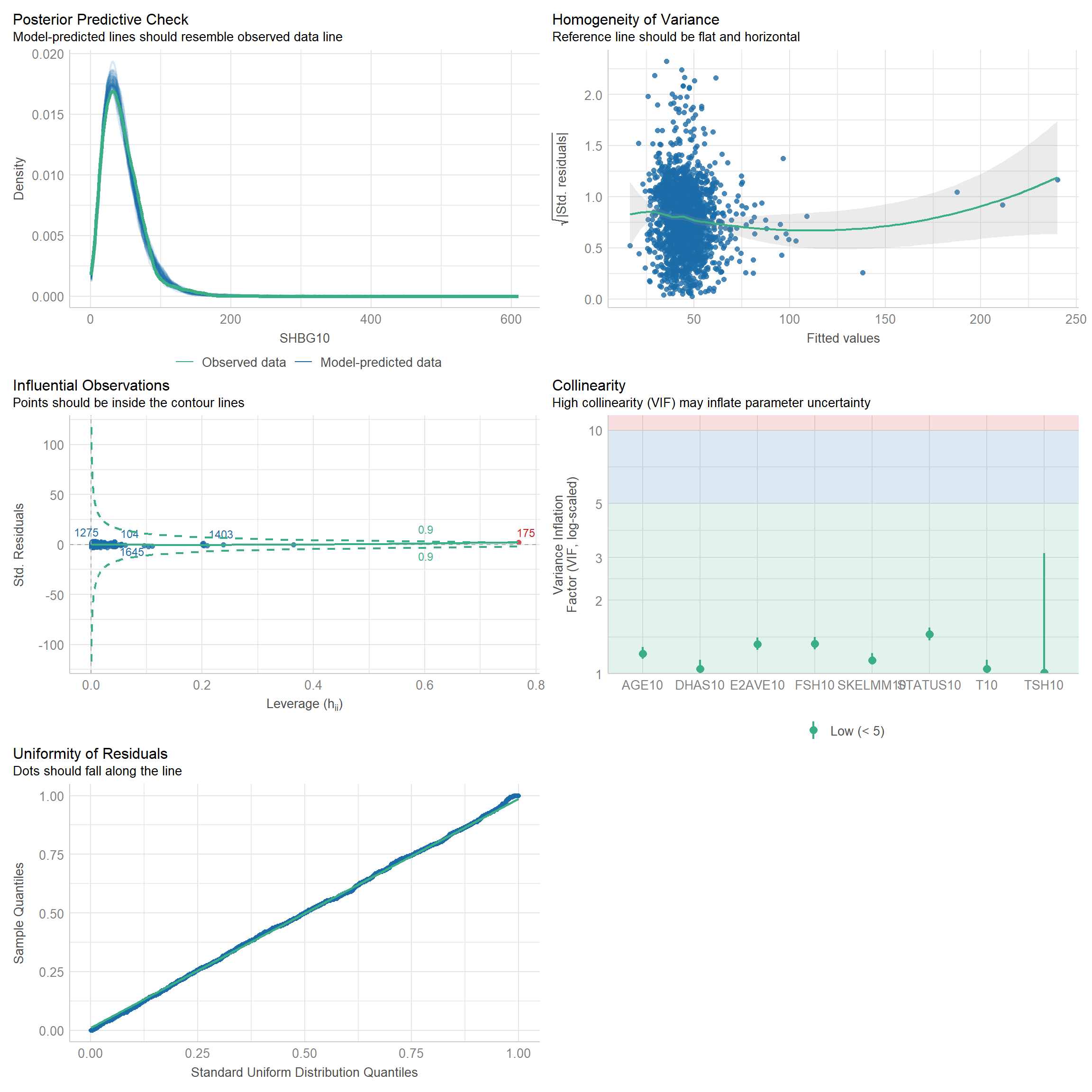
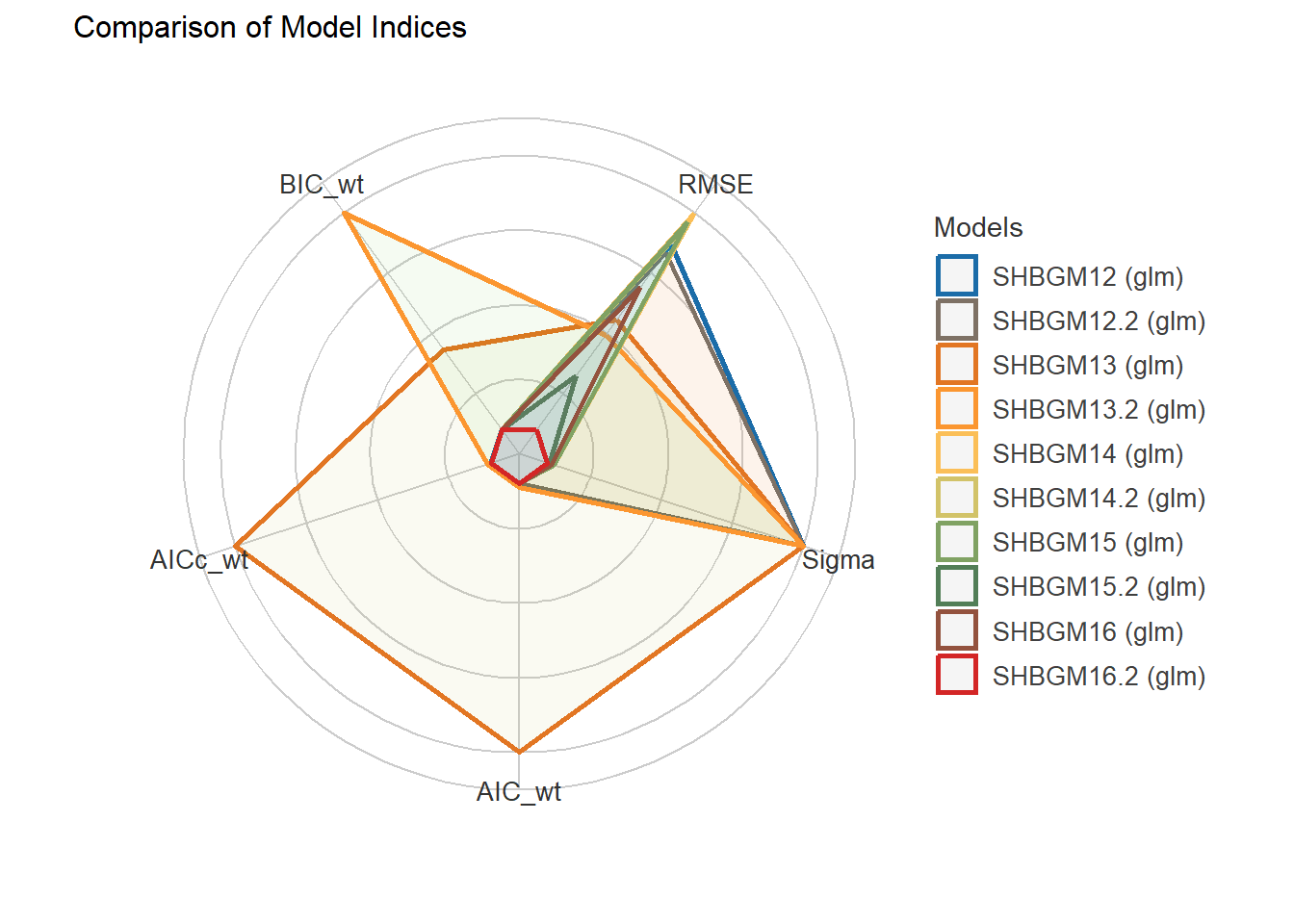
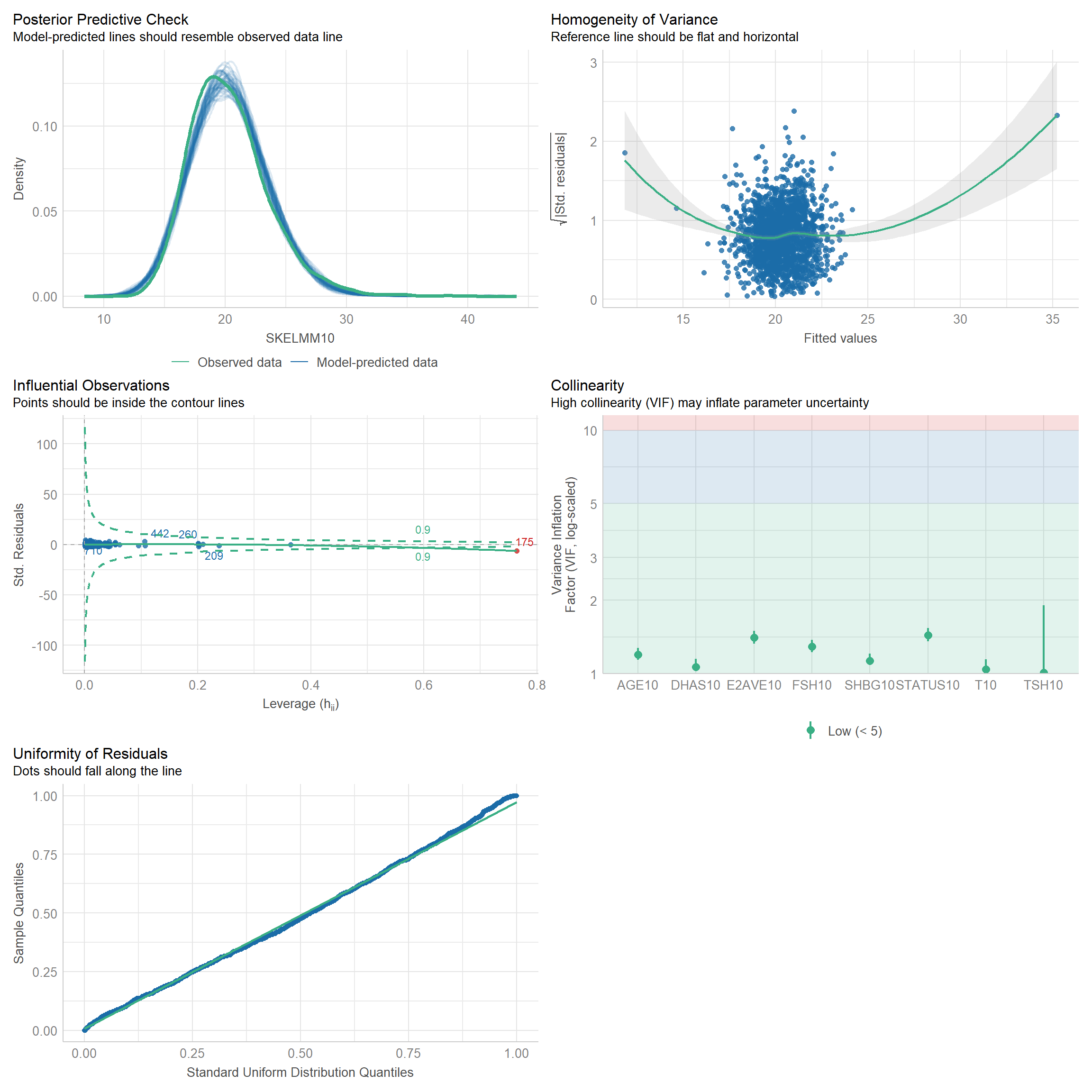
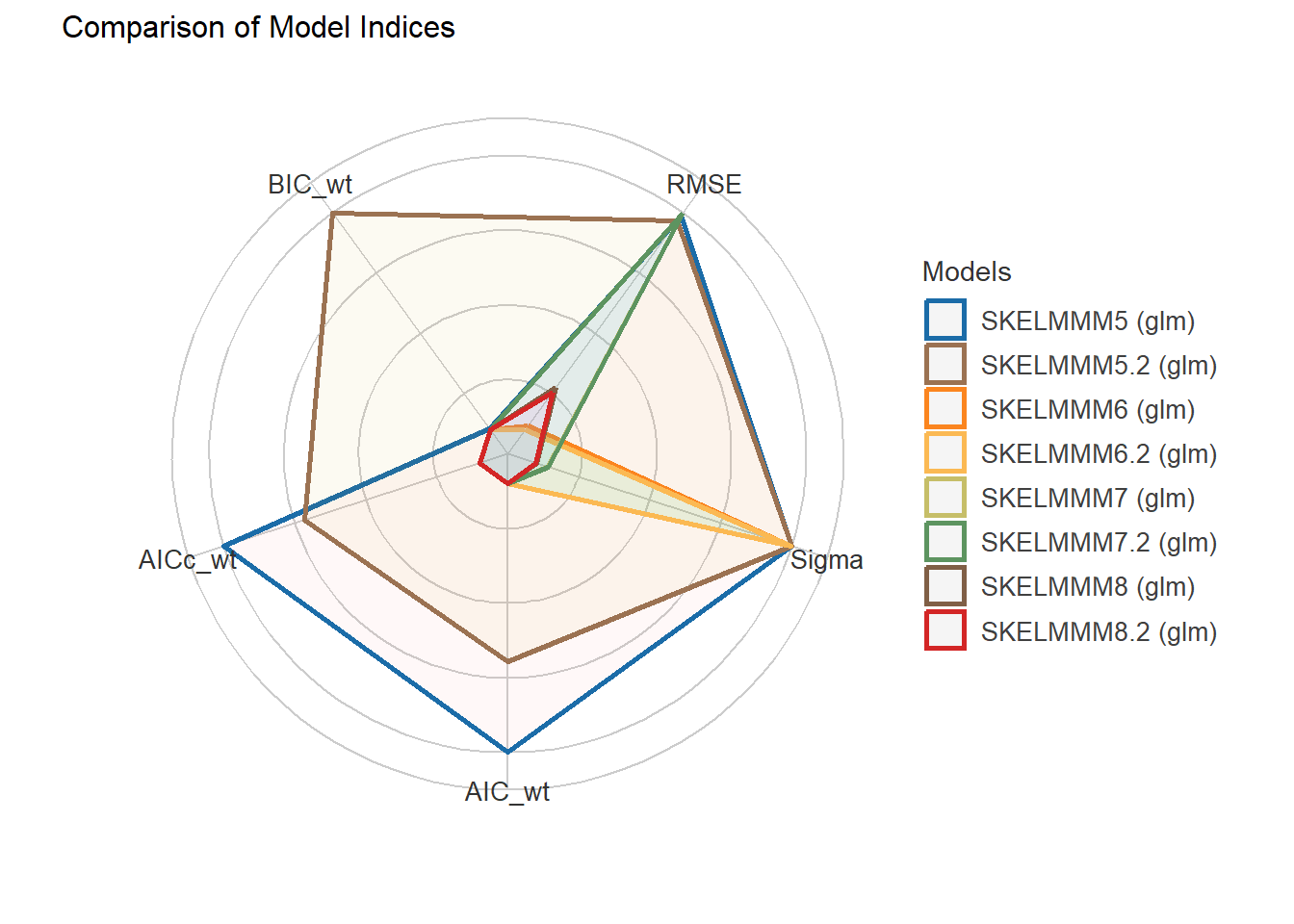
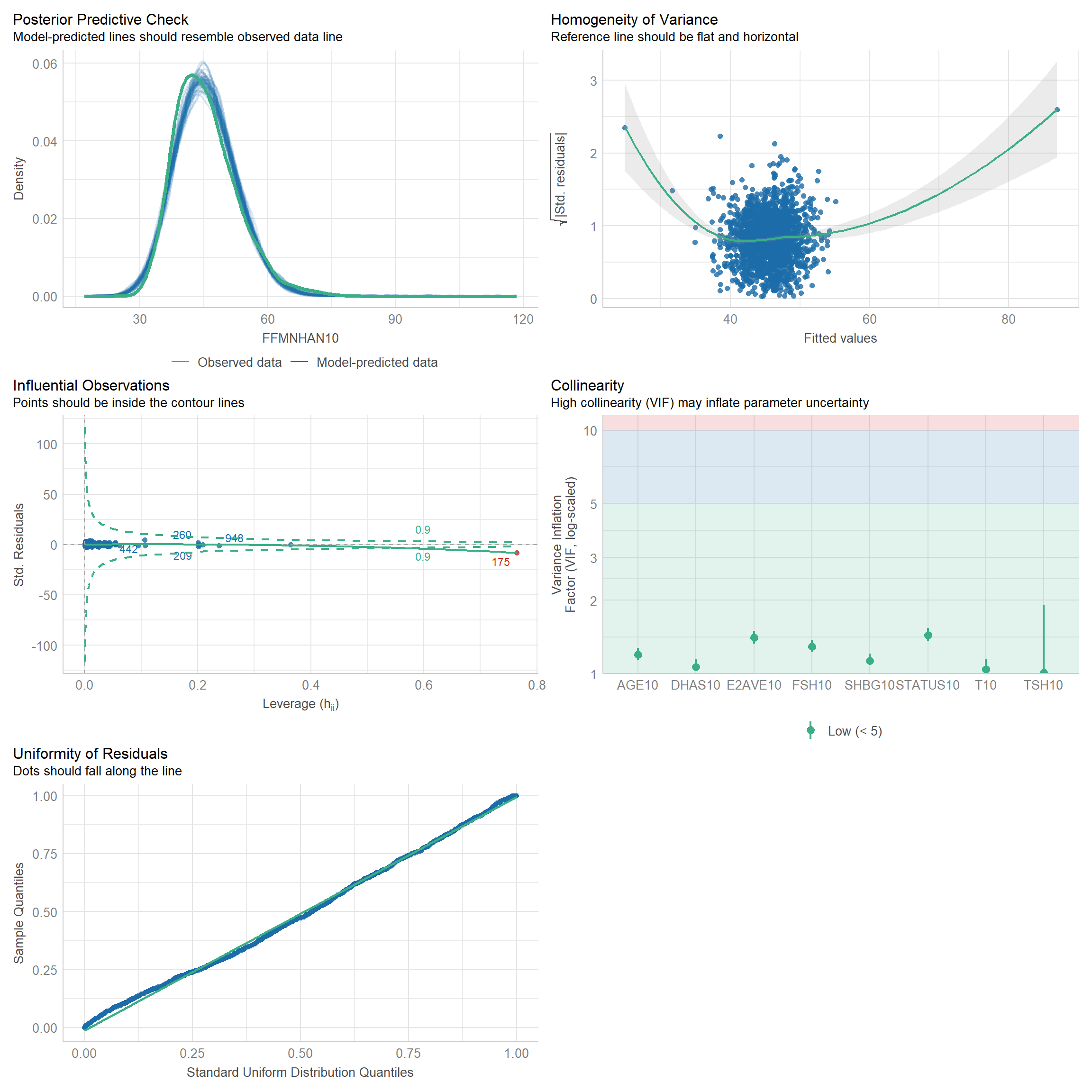
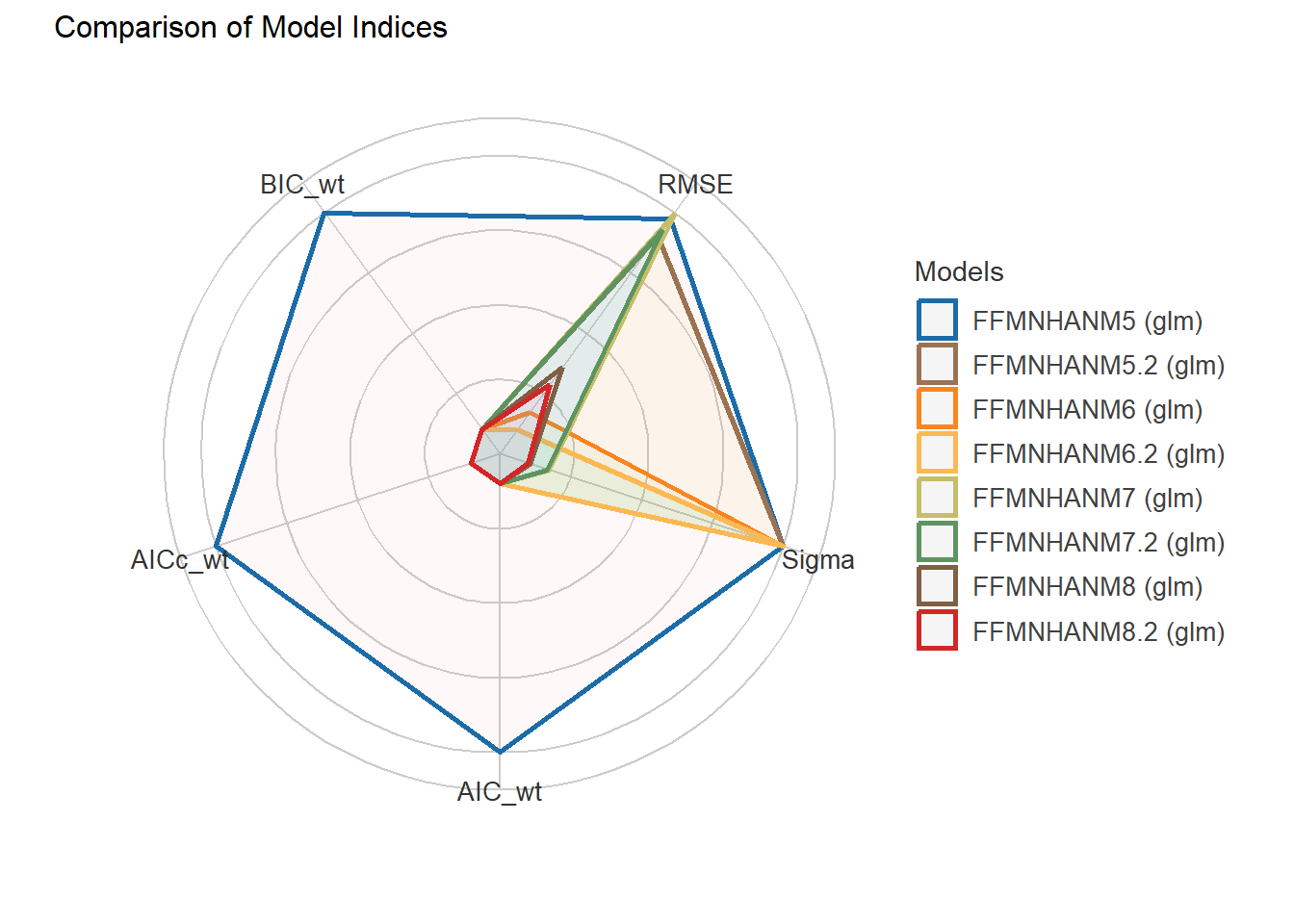
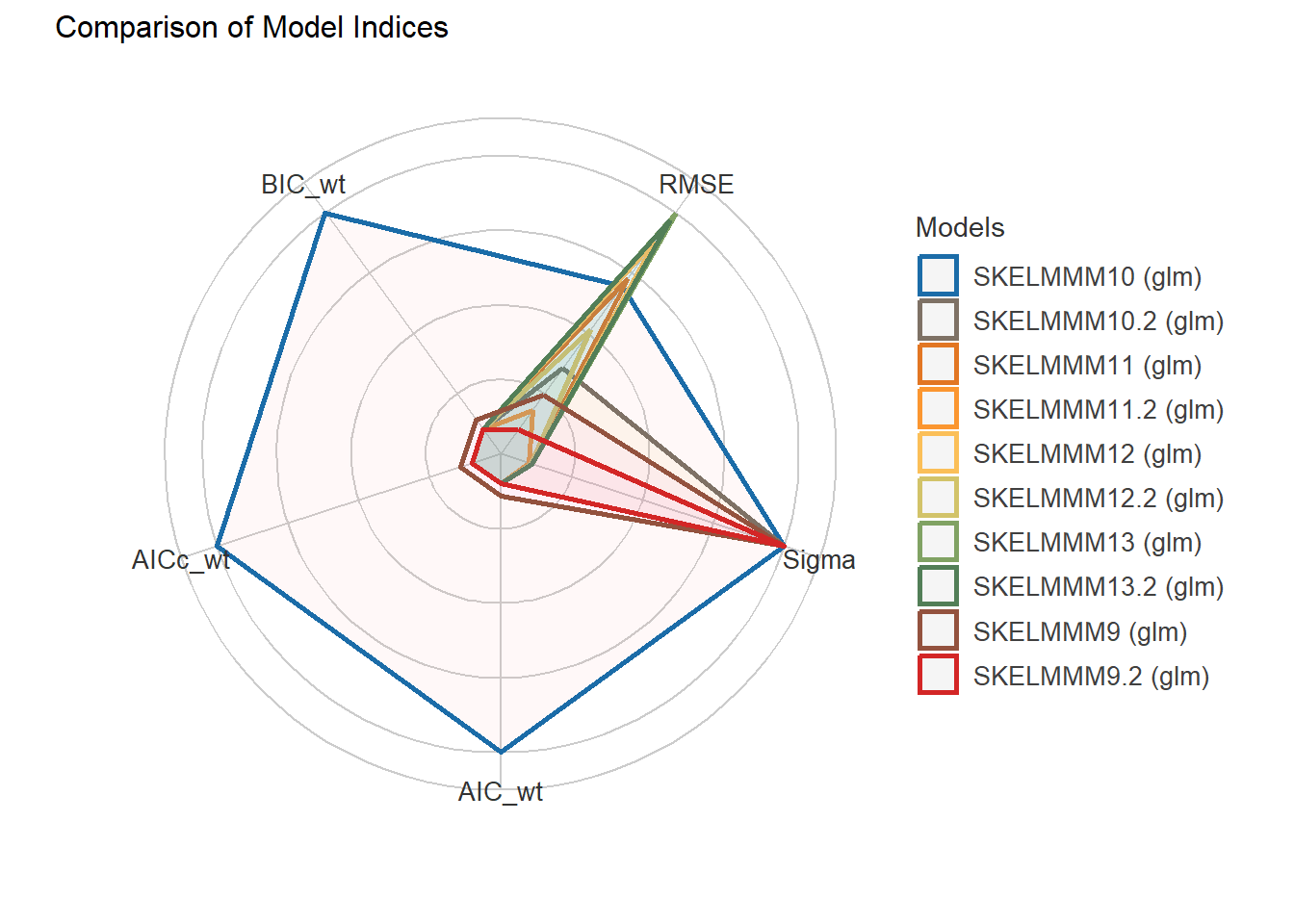
11 Generalized linear regression models (GLM) for dependent variable: SHBG
11.1 Independent variable: Hormones + SKELMM + AGE + STATUS + OTHERS.